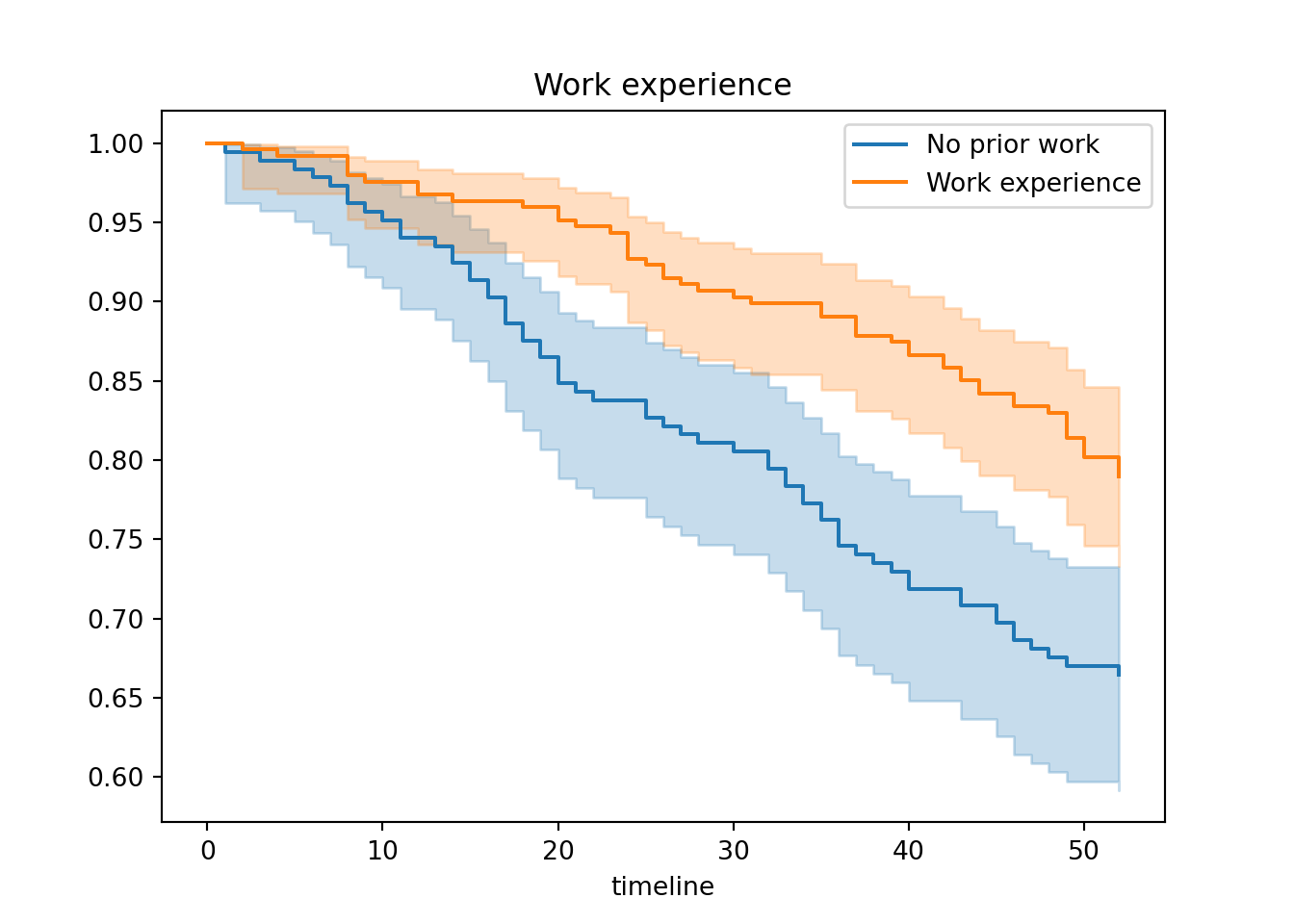
Chapter 6 Extras
6.1 Using Lasso
## Loading required package: Matrix## Loaded glmnet 4.1-7x=GBSG2 %>% select(horTh,age,menostat,tsize, tgrade, pnodes, progrec, estrec)
y=Surv(time=GBSG2$time,event=GBSG2$cens)
model1<-glmnet(x,y,family="cox")
plot(model1,label=T)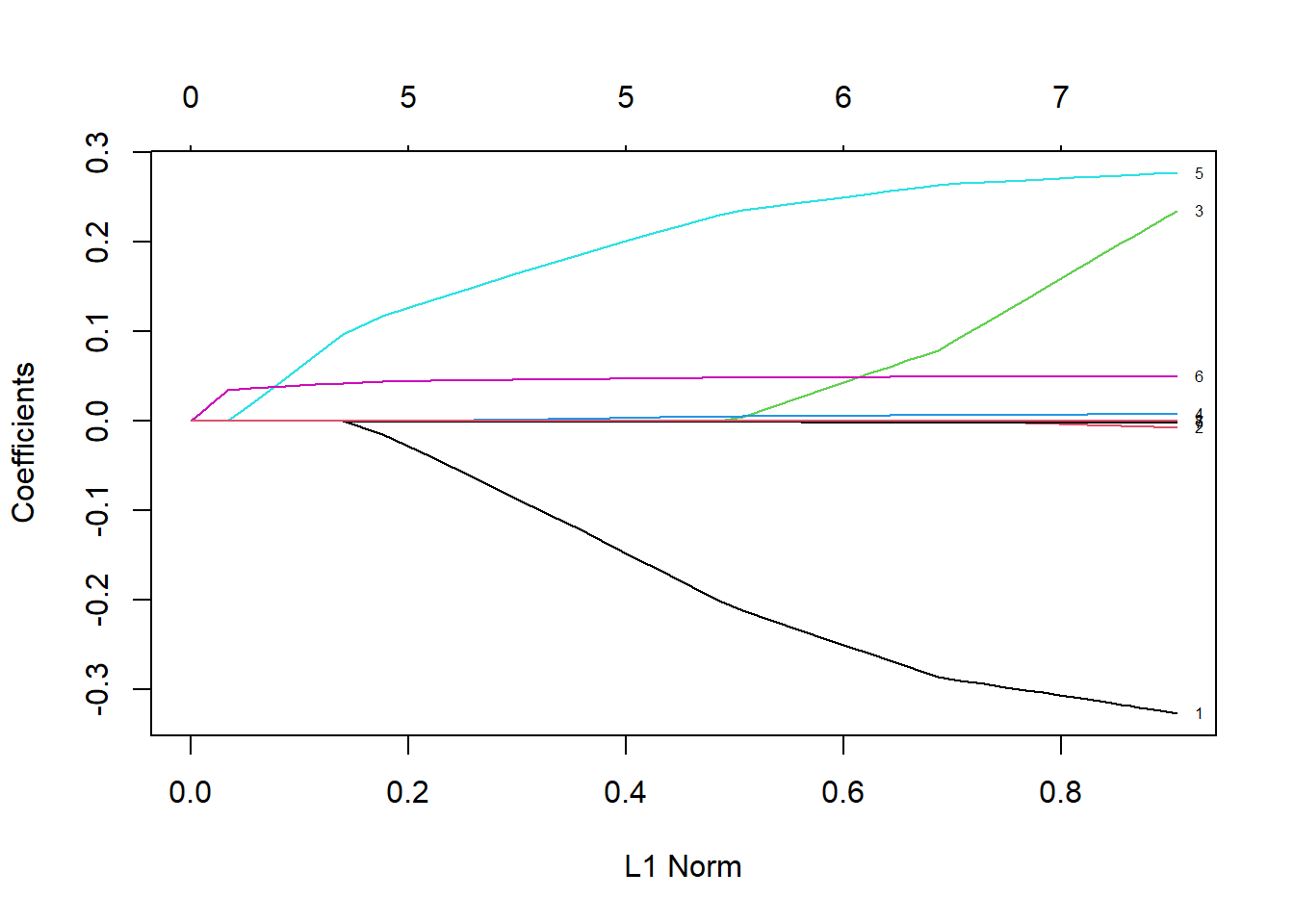
x1=x %>% mutate(horTh2=if_else(horTh=="no",0,1),menostat2=if_else(menostat=="Pre",0,1),tgrade2=if_else(tgrade=="I",1,0),tgrade3=if_else(tgrade=="II",1,0)) %>% select(horTh2,age,menostat2,tgrade2,tgrade3,tsize,pnodes,progrec,estrec)
x1<-as.matrix(x1)
set.seed(1287)
cvfit <- cv.glmnet(x1, y, family = "cox", type.measure = "C")
plot(cvfit)
plot(cvfit)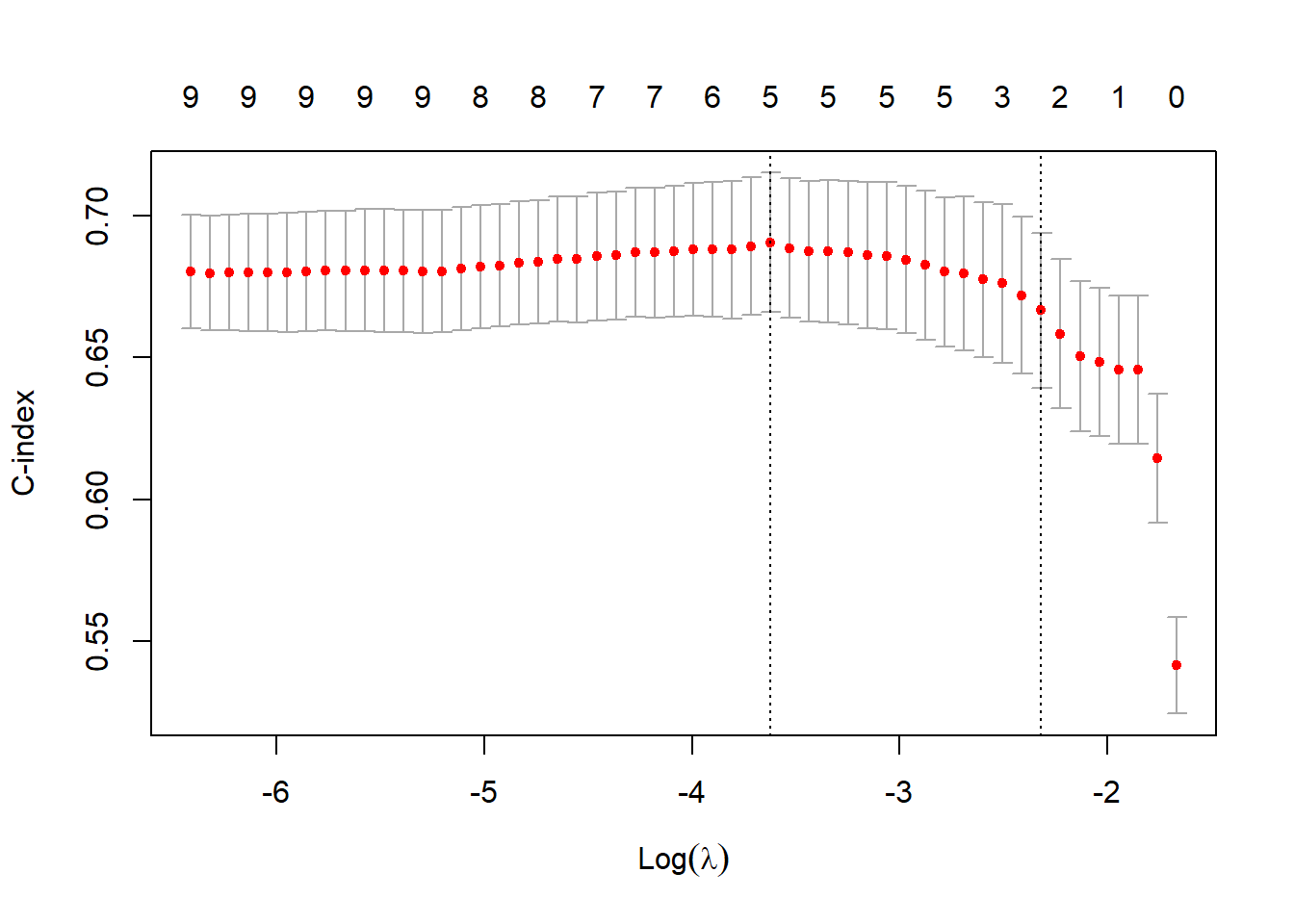
## [1] 0.02673542## [1] 0.09834302## 8 x 1 sparse Matrix of class "dgCMatrix"
## 1
## horTh -0.176785737
## age .
## menostat .
## tsize 0.004002226
## tgrade 0.216889004
## pnodes 0.047722334
## progrec -0.001325963
## estrec .## 8 x 1 sparse Matrix of class "dgCMatrix"
## 1
## horTh .
## age .
## menostat .
## tsize .
## tgrade 0.0153489911
## pnodes 0.0362199648
## progrec -0.0001341727
## estrec .Can also do repeated events and stratified analysis, see https://glmnet.stanford.edu/articles/Coxnet.html.
6.2 Decision Trees
## Warning: package 'partykit' was built under R version 4.3.2## Loading required package: grid## Loading required package: libcoin## Loading required package: mvtnorm##
## Model formula:
## Surv(time, cens) ~ horTh + age + menostat + tsize + tgrade +
## pnodes + progrec + estrec
##
## Fitted party:
## [1] root
## | [2] pnodes <= 3
## | | [3] horTh in no: 2093.000 (n = 248)
## | | [4] horTh in yes: Inf (n = 128)
## | [5] pnodes > 3
## | | [6] progrec <= 20: 624.000 (n = 144)
## | | [7] progrec > 20: 1701.000 (n = 166)
##
## Number of inner nodes: 3
## Number of terminal nodes: 4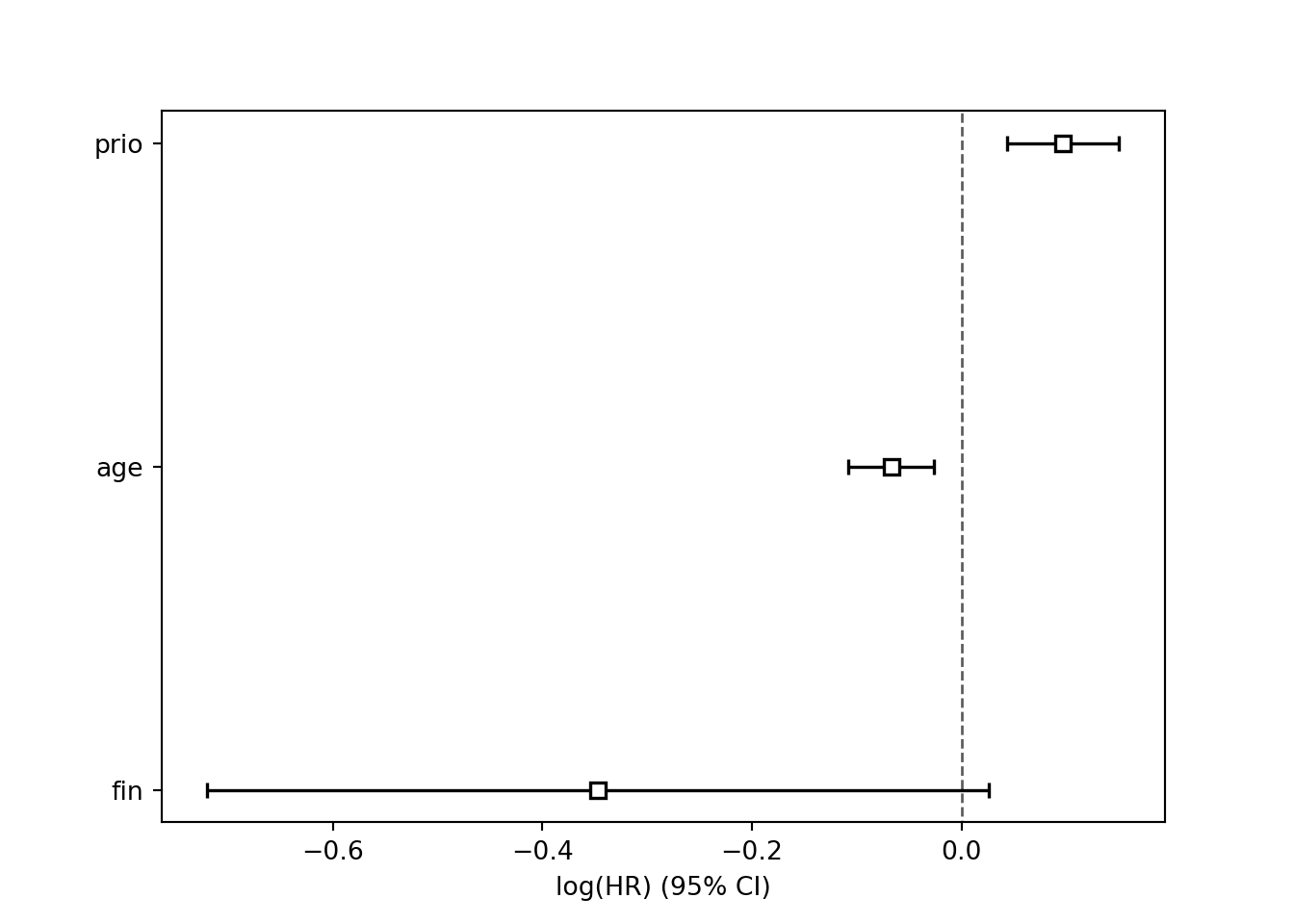
## 1 2
## 3 7## 1 2
## 2093 1701This is using conditional trees in the partykit package in R. Good reference for more information is https://cran.r-project.org/web/packages/partykit/vignettes/ctree.pdf.
6.3 Random Forest
## Warning: package 'randomForestSRC' was built under R version 4.3.2##
## randomForestSRC 3.2.2
##
## Type rfsrc.news() to see new features, changes, and bug fixes.
## ##
## Attaching package: 'randomForestSRC'## The following object is masked from 'package:Hmisc':
##
## impute## Warning: package 'ggRandomForests' was built under R version 4.3.2## Loading required package: randomForest## Warning: package 'randomForest' was built under R version 4.3.2## randomForest 4.7-1.1## Type rfNews() to see new features/changes/bug fixes.##
## Attaching package: 'randomForest'## The following object is masked from 'package:dplyr':
##
## combine## The following object is masked from 'package:ggplot2':
##
## marginsurv.rf <- rfsrc(Surv(time,cens) ~ . ,data=GBSG2,importance = TRUE,splitrule="logrankscore")
print(surv.rf$importance)## horTh age menostat tsize tgrade pnodes
## 0.009844800 0.106266170 0.005833365 0.049241546 0.052994434 0.094097024
## progrec estrec
## 0.095148255 0.045038185## Sample size: 686
## Number of deaths: 299
## Number of trees: 500
## Forest terminal node size: 15
## Average no. of terminal nodes: 30.148
## No. of variables tried at each split: 3
## Total no. of variables: 8
## Resampling used to grow trees: swor
## Resample size used to grow trees: 434
## Analysis: RSF
## Family: surv
## Splitting rule: logrankscore *random*
## Number of random split points: 10
## (OOB) CRPS: 0.16637673
## (OOB) Requested performance error: 0.30355211##
|
| | 0%
|
|= | 1%
|
|= | 2%
|
|== | 3%
|
|=== | 4%
|
|==== | 5%
|
|==== | 6%
|
|===== | 7%
|
|====== | 8%
|
|====== | 9%
|
|======= | 10%
|
|======== | 11%
|
|======== | 12%
|
|========= | 13%
|
|========== | 14%
|
|========== | 15%
|
|=========== | 16%
|
|============ | 17%
|
|============= | 18%
|
|============= | 19%
|
|============== | 20%
|
|=============== | 21%
|
|=============== | 22%
|
|================ | 23%
|
|================= | 24%
|
|================== | 25%
|
|================== | 26%
|
|=================== | 27%
|
|==================== | 28%
|
|==================== | 29%
|
|===================== | 30%
|
|====================== | 31%
|
|====================== | 32%
|
|======================= | 33%
|
|======================== | 34%
|
|======================== | 35%
|
|========================= | 36%
|
|========================== | 37%
|
|=========================== | 38%
|
|=========================== | 39%
|
|============================ | 40%
|
|============================= | 41%
|
|============================= | 42%
|
|============================== | 43%
|
|=============================== | 44%
|
|================================ | 45%
|
|================================ | 46%
|
|================================= | 47%
|
|================================== | 48%
|
|================================== | 49%
|
|=================================== | 50%
|
|==================================== | 51%
|
|==================================== | 52%
|
|===================================== | 53%
|
|====================================== | 54%
|
|====================================== | 55%
|
|======================================= | 56%
|
|======================================== | 57%
|
|========================================= | 58%
|
|========================================= | 59%
|
|========================================== | 60%
|
|=========================================== | 61%
|
|=========================================== | 62%
|
|============================================ | 63%
|
|============================================= | 64%
|
|============================================== | 65%
|
|============================================== | 66%
|
|=============================================== | 67%
|
|================================================ | 68%
|
|================================================ | 69%
|
|================================================= | 70%
|
|================================================== | 71%
|
|================================================== | 72%
|
|=================================================== | 73%
|
|==================================================== | 74%
|
|==================================================== | 75%
|
|===================================================== | 76%
|
|====================================================== | 77%
|
|======================================================= | 78%
|
|======================================================= | 79%
|
|======================================================== | 80%
|
|========================================================= | 81%
|
|========================================================= | 82%
|
|========================================================== | 83%
|
|=========================================================== | 84%
|
|============================================================ | 85%
|
|============================================================ | 86%
|
|============================================================= | 87%
|
|============================================================== | 88%
|
|============================================================== | 89%
|
|=============================================================== | 90%
|
|================================================================ | 91%
|
|================================================================ | 92%
|
|================================================================= | 93%
|
|================================================================== | 94%
|
|================================================================== | 95%
|
|=================================================================== | 96%
|
|==================================================================== | 97%
|
|===================================================================== | 98%
|
|===================================================================== | 99%
|
|======================================================================| 100%par(cex.axis = 2.0, cex.lab = 2.0, cex.main = 2.0, mar = c(6.0,17,1,1), mgp = c(4, 1, 0))
plot(imp.val, xlab = "Variable Importance (x 100)", cex = 1.2)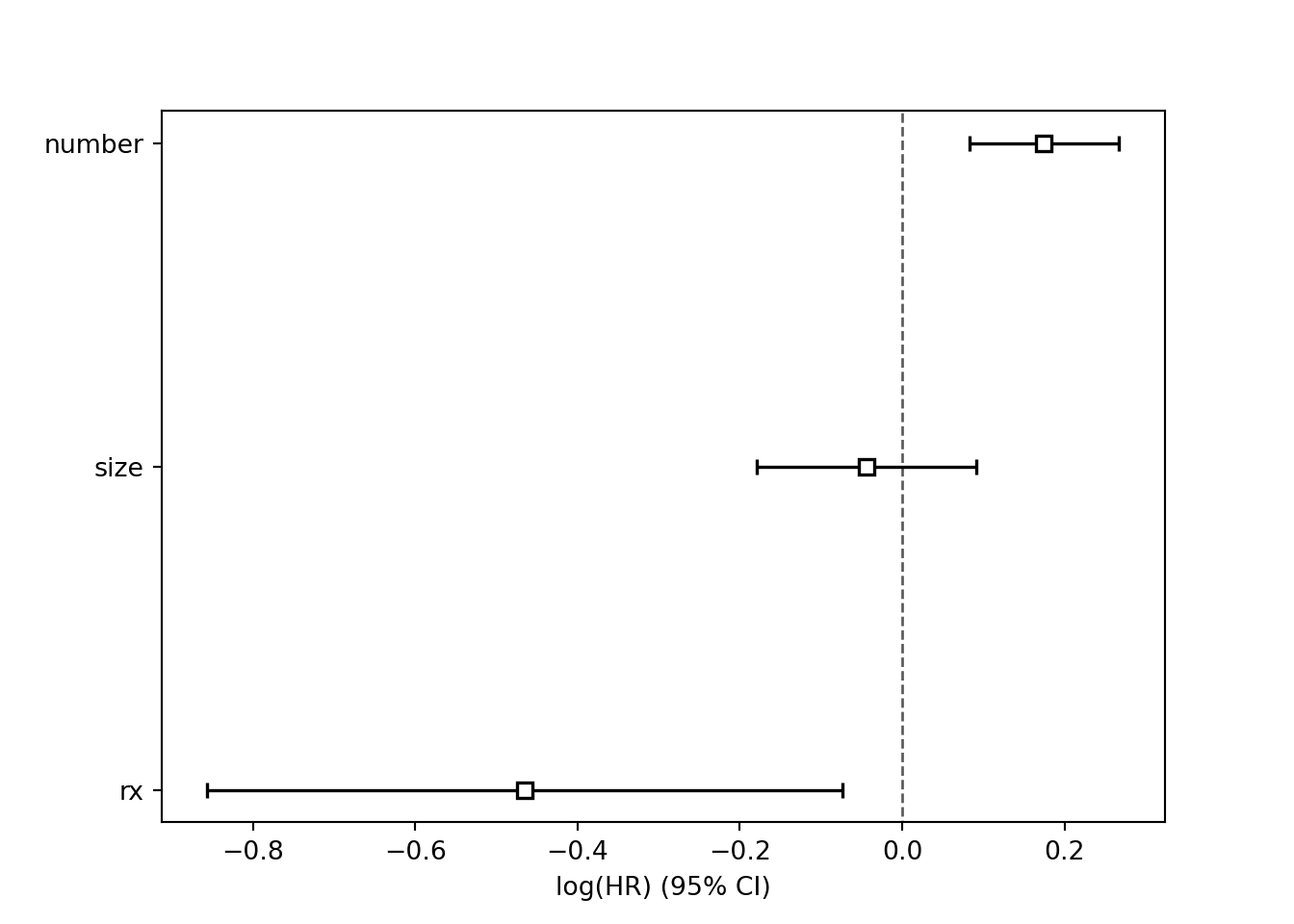
newdat1=GBSG2[1:2,-c(9:10)]
pred.surv=predict(surv.rf,newdata=newdat1)
graph.surv=cbind.data.frame(c(rep(1,length(pred.surv$survival[1,])),rep(2,length(pred.surv$survival[2,]))),c(pred.surv$time.interest,pred.surv$time.interest),c(pred.surv$survival[1,],pred.surv$survival[2,]))
colnames(graph.surv)=c("Person","Time","Survival")
ggplot(graph.surv,aes(x=Time,y=Survival,group=Person))+geom_line()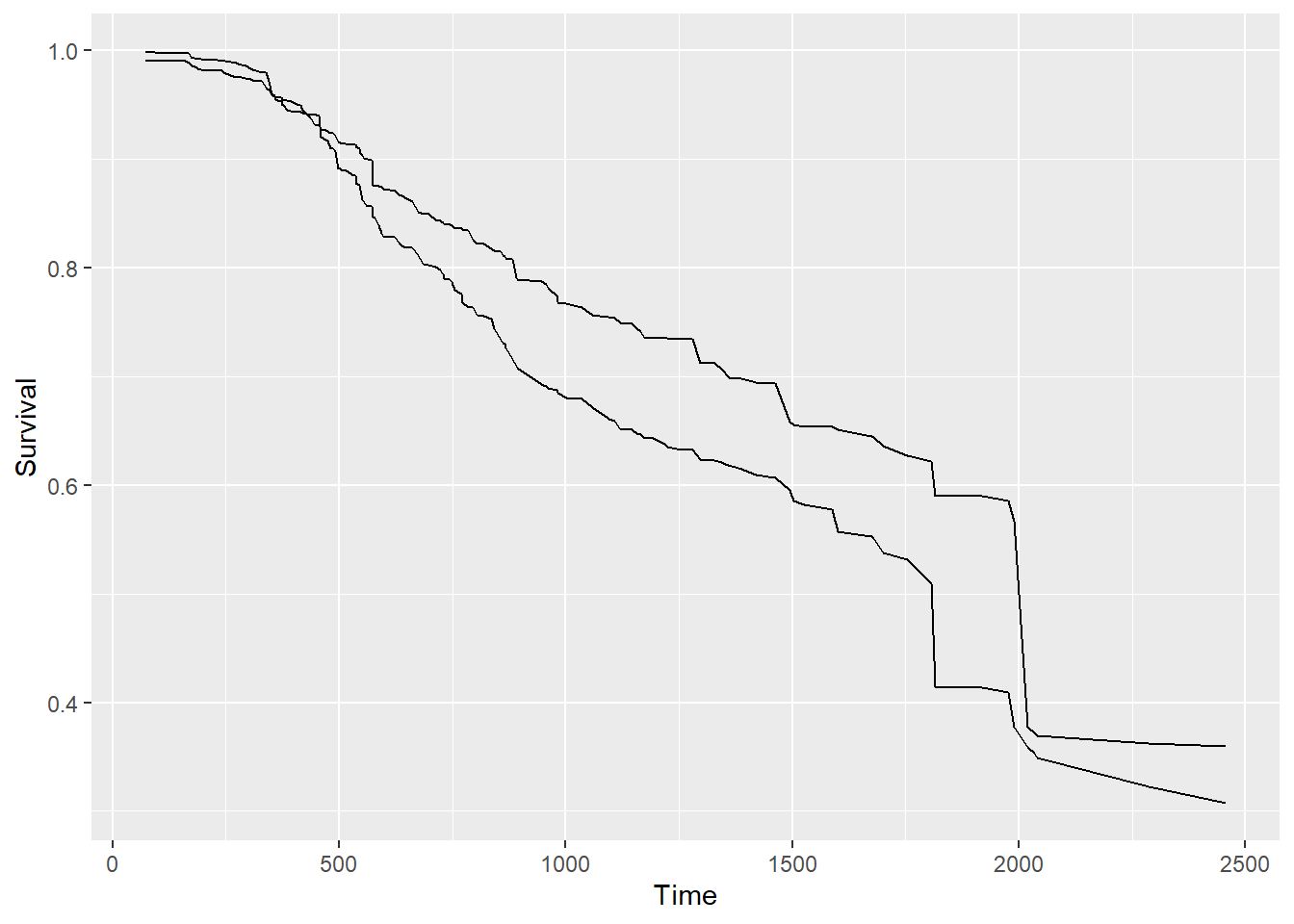
For more information, see https://www.randomforestsrc.org/articles/survival.html, https://www.randomforestsrc.org/index.html for the Survival Random Forest or https://cran.microsoft.com/snapshot/2014-12-19/web/packages/ggRandomForests/vignettes/randomForestSurvival.pdf for nice visuals using the ggRandomForest package.
6.4 Python
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn import set_config
from sklearn.preprocessing import OrdinalEncoder
from sksurv.datasets import load_gbsg2
from sksurv.ensemble import RandomSurvivalForest
from sksurv.linear_model import CoxPHSurvivalAnalysis, CoxnetSurvivalAnalysis
from sksurv.preprocessing import OneHotEncoder
set_config(display="text")
X, y = load_gbsg2()
def plot_coefficients(coefs, n_highlight):
_, ax = plt.subplots(figsize=(9, 6))
n_features = coefs.shape[0]
alphas = coefs.columns
for row in coefs.itertuples():
ax.semilogx(alphas, row[1:], ".-", label=row.Index)
alpha_min = alphas.min()
top_coefs = coefs.loc[:, alpha_min].map(abs).sort_values().tail(n_highlight)
for name in top_coefs.index:
coef = coefs.loc[name, alpha_min]
plt.text(alpha_min, coef, name + " ", horizontalalignment="right", verticalalignment="center")
ax.yaxis.set_label_position("right")
ax.yaxis.tick_right()
ax.grid(True)
ax.set_xlabel("alpha")
ax.set_ylabel("coefficient")
grade_str = X.loc[:, "tgrade"].astype(object).values[:, np.newaxis]
grade_num = OrdinalEncoder(categories=[["I", "II", "III"]]).fit_transform(grade_str)
X_no_grade = X.drop("tgrade", axis=1)
Xt = OneHotEncoder().fit_transform(X_no_grade)
Xt.loc[:, "tgrade"] = grade_num
###Lasso
cox_lasso = CoxnetSurvivalAnalysis(l1_ratio=1.0, alpha_min_ratio=0.01)
cox_lasso.fit(Xt, y)## CoxnetSurvivalAnalysis(alpha_min_ratio=0.01, l1_ratio=1.0)coefficients_lasso = pd.DataFrame(cox_lasso.coef_, index=Xt.columns, columns=np.round(cox_lasso.alphas_, 5))
plot_coefficients(coefficients_lasso, n_highlight=5)
plt.show()
## Random Survival Forest
rsf = RandomSurvivalForest(
n_estimators=1000, min_samples_split=10, min_samples_leaf=15, n_jobs=-1, random_state=23987)
rsf.fit(Xt, y)## RandomSurvivalForest(min_samples_leaf=15, min_samples_split=10,
## n_estimators=1000, n_jobs=-1, random_state=23987)## 0.76956083924492## array([[1. , 1. , 1. , ..., 0.31035269, 0.31035269,
## 0.31035269],
## [1. , 1. , 1. , ..., 0.31250991, 0.31250991,
## 0.31250991]])for i, s in enumerate(surv):
plt.step(rsf.unique_times_, s, where="post")
plt.ylabel("Cumulative hazard")
plt.xlabel("Time in days")
plt.legend()
plt.grid(True)
plt.show()